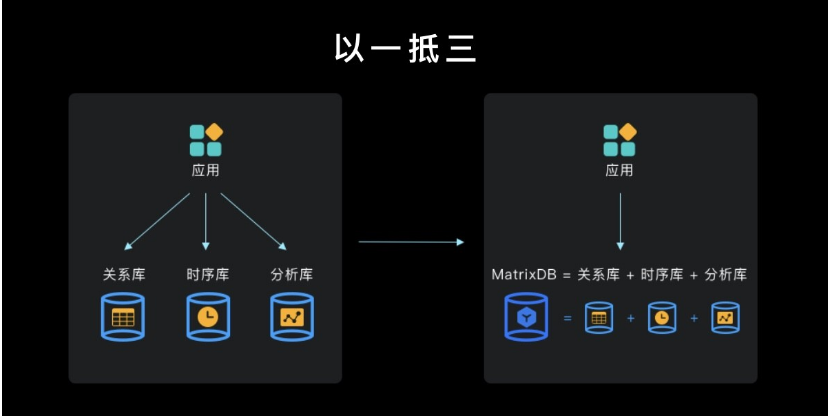
我们可以看到,在进化了近50年后,现有的数据库技术已经不能满足从业者的需求 --- 他们需要更加简单易用、省心省力的数据库。在这样的背景下,为了能给用户提供简单易用的接口,真正实现数据平民化,姚延栋和他的团队将关系数据库、时序数据库和分析数据库融合在同一个数据库产品中,打造了全球唯一一款PB级超融合时序数据库--MatrixDB。
超融合时序数据库解决了什么问题?
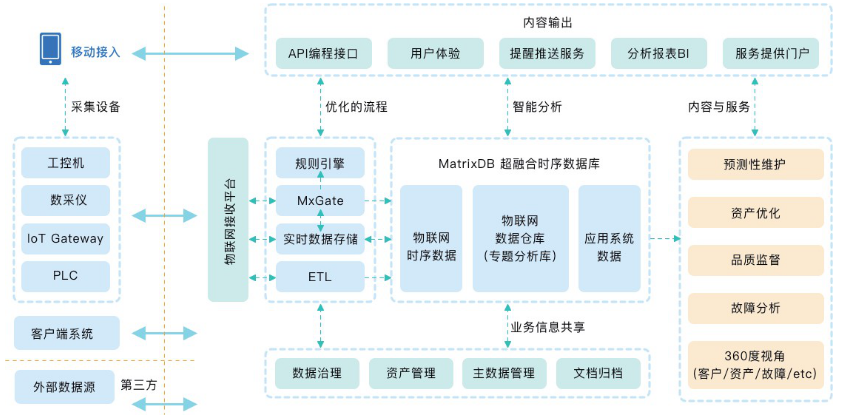
目前,超融合时序数据库主要应用在两大场景:第一,时序、时空场景,通常是物联网、工业互联网、车联网和智慧城市等领域;第二,实时数据分析场景。
谈到时序、时空场景,姚延栋分享了一个海量设备、大量存储的典型物联网场景。“以一家做光纤和5G通讯设备的国际制造商为例,这家制造商大概有1000万设备,每台设备每次都会采集300个指标数据,每次共计需要采集30亿指标。”基于这种情况下,MatrixDB实现了超大规模数据的实时加载特性,在保证低延迟和高并发加载的同时,也减轻了系统资源消耗,充分将快速采集、高效存储的特性显示了出来,使得海量数据的存储问题、秒级采集的频率要求都能得到完美的解决。
在实时分析的特性方面,姚延栋又给出了另一个案例:在一个实时数据分析的业务中,MatrixDB可以实现对IT运营域和OT生产域的数据收集,通过ETL/CDC和物联网协议插入数据以后,便能将两张网的数据整合在一起,使得公司的全部数据一目了然地展现。当企业再基于这些数据进行分析时,就能得到更加精准且全面的结论。
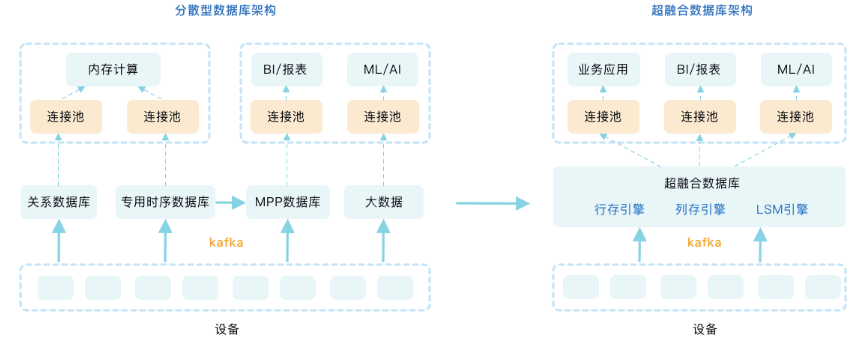
我们还注意到了MatrixDB的另一个重要特性――模块化和可插拔。专用时序数据库通常包含存储器和简单的执行器,没有优化器和并发控制等关系数据库经典组件。从本质上来看,它是把存储器“做成”了数据库,以此来解决一个特定的问题。而超融合时序数据库则是把存储器“做进”数据库,通过把各个核心功能做到模块化、可插拔,在一个关系数据库内部同时实现多种存储引擎,以及跨存储表关联和ACID。比如有200张表,其中190张是关系型数据,这部分可以使用关系引擎存储;剩余10张是时序数据,就可以使用时序引擎存储,且它们可以相互关联。
与传统的关系数据库+专用时序数据库相结合的架构相比,通过支持多种存储引擎,超融合时序数据库可以让性能快10-100倍,同时大幅降低成本,提升开发运维效率。
令人惊喜的是,除了快速采集、高效存储、实时分析以及模块化和可插拔特性以外,我们注意到MatrixDB作为一款数据库产品,还提供了机器学习的能力。随着人工智能技术的飞速发展,In-Database Machine Learning成为一个值得关注的方向,将机器学习的算法内置到数据库将逐渐成为主流。一方面,借助分布式数据库的并行计算能力,可以使计算速度超越单机;另一方面,由于单机上的内存有限,在数据量很大的情况下,只能抽样进行训练,模型精度就会变差。通过In-Database Machine Learning模式,就能实现在全量数据上训练,模型精度也将得到进一步提高。
“过去从业者需要自己写程序才能实现机器学习。”这是姚延栋提到的一个现象,并表示这其中的技术门槛比较高。“目前,MatrixDB数据库通过直接提供SQL接口,大大降低了机器学习的门槛,能够在一定程度上缓解人才稀缺的问题”。
 高层
高层 访谈
访谈

 观点
观点
