飞象网讯(魏德龄/文)当下,拥有实时运行特性的人工智能应用正开始在日常生活中占据重要角色,最典型的例子就是实时的语音转文字、聊天机器人这类应用,在使用过程中即时响应速度关乎着实际体验感受。而企业为了保证时延,又往往不得不缩减模型大小。最终却可能让用户实际体验时出现不怎么快也不怎么准的问题,英伟达刚刚发布的TensorRT 8恰恰将助力这类实时AI应用能够更快更好。
性能精度均提升2倍
一直以来,英伟达在AI领域的布局都不止于硬件,TensorRT就是重要佐证之一,作为用于高性能深度学习推理的SDK。此SDK包含深度学习推理优化器和运行时环境,可为深度学习推理应用提供低延迟和高吞吐量。
通过TensorRT,开发者可将TensorFlow、Pytorch等训练好的框架模型,通过优化后良好的运行在英伟达的GPU上。在2019年发布的NVIDIA TensorRT 7已经为智能的AI人际交互打开了大门,可实现与语音代理、聊天机器人和推荐引擎等应用的实时互动。
TensorRT 7配合A100 GPU可实现在2.5毫秒内运行BERT-Large,此次新发布的TensorRT 8将时间缩减至1.2毫秒。作为目前最广为采用的基于transformer的模型之一,意味着理论上当用户在使用如实时语音翻译这样的功能时,TensorRT 8的处理延迟时间可降至1.2毫秒。
TensorRT 8相比TensorRT 7有着两倍性能提升的同时,精度也同样提升2倍。TensorRT 8在两方面实现了AI推理上的突破,一方面提升了对于英伟达Ampere架构GPU的稀疏性,在提升效率的同时还能减少开发者加速神经网络时的计算操作。另一方面是量化感知训练,开发者能够使用训练好的模型,以INT8精度运行推理,在这一过程中不会损失精度。
这就意味着,企业可以将模型扩大1-2倍,实现精度的大幅提升,让自身的实时AI应用变得又快又好。
为多领域带来更快更好的AI能力
当前,TensorRT的生态影响力正在快速增长,2020年的开发者人数相比2019年就实现了3倍的增长,达到35万人,下载量已经达到近250万次,共有从边缘到云的多个领域的共27500家公司加入到该生态之中。其中包括如电信运营商Verizon,也有国内的知名互联网公司阿里、腾讯、字节跳动等。
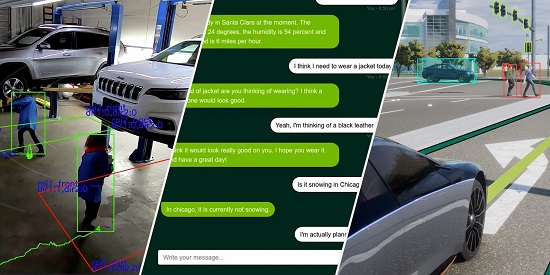
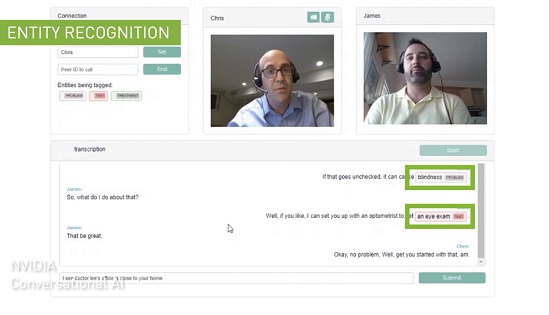
TensorRT 8的发布无疑将会让搜索、购物推荐、语音翻译、语音转文字这样的AI应用能够实现更快更好。Hugging Face就正在与英伟达开展密切合作,作为大规模AI服务提供商,Hugging Face加速推理API能够为基于NVIDIA GPU的transformer模型提供高达100倍的速度提升,通过TensorRT 8,Hugging Face在BERT上实现了1毫秒的推理延迟,为助力实现大规模文本分析、神经搜索和对话式应用的AI服务提供加速度。
据悉,TensorRT目前还应用在了临床医疗领域,GE医疗就通过TensorRT来助力加速超声波计算机视觉应用,这是一款早期检测疾病的关键工具。TensorRT的实时推理能力提高了视图检测算法的性能,缩短了产品上市时间。实际工作中可让扫描仪在进行自动心脏视图检测时更高效,心脏视图识别算法会选择合适的图像来分析心壁运动。
 高层
高层 访谈
访谈

 观点
观点
