近年来,大模型发展在人工智能领域引起了广泛的兴趣与关注,庞大的规模和学习能力使其具备了出色的性能和表现。近日,IDEA研究院(粤港澳大湾区数字经济研究院)宣布开源通用大模型系列“姜子牙”,让广大开发者可以共同参与模型的改进、优化和拓展,通过分享经验和创意,推动模型的进步和创新。与IDEA建立合作,UCloud镜像市场也上线了姜子牙大模型镜像,基于UCloud强大的云计算基础设施,客户可以轻松创建预装姜子牙大模型的云主机,并享受高性能的GPU算力资源。
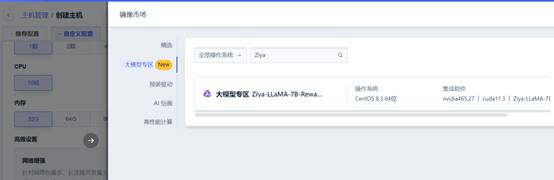
“姜子牙通用大模型v1”是由IDEA开发的一款领先的自然语言处理模型。基于LLaMa的130亿参数的大规模预训练模型,具备翻译、编程、文本分类、信息抽取、摘要、文案生成、常识问答和数学计算等能力。目前姜子牙通用大模型v1已完成大规模预训练、多任务有监督微调和人类反馈学习三阶段的训练过程。
本次UCloud上线的是姜子牙大模型的Ziya-LLaMA-7B-Reward模型镜像。该模型基于Ziya-LLaMA模型,在自标注高质量偏好排序数据、严格过滤的外部开源数据这两个偏好排序数据上进行训练。同时该模型能够模拟中英双语生成的奖励环境,对LLM生成结果提供准确的奖励反馈。
作为最新一代发布的大语言模型,“姜子牙通用大模型v1”具备以下三个方面的优势:
1、全面的数据训练:使用来自多个领域和多种来源的原始数据进行预训练,包括英文和中文数据。通过去重、打分、分桶、规则过滤和数据评估等处理,最终得到125B tokens的有效数据。这种全面的数据训练使得模型具备广泛的语言知识和理解能力。
2、高效的中文编解码:通过扩充词表、优化分词方式,提升了对中文的编解码效率。通过增加常见中文字并复用Transformers中的LlamaTokenizer,实现了高效的中文处理能力。
3、多任务有监督微调和人类反馈训练:在多任务有监督微调阶段采用课程学习和增量训练的策略,通过"Easy To Hard"的方式进行训练。同时,通过人类反馈训练进一步提升模型的综合表现。人类反馈训练采用了以人类反馈强化学习为主的方法,结合多种其他手段联合训练,包括人类反馈微调、后见链微调、AI反馈和基于规则的奖励系统等。这些训练方法使得模型能够更好地理解人类意图、减少错误输出,并提高整体性能。
这些优势使得姜子牙大模型成为一款强大的自然语言处理模型,不仅在语言知识和理解能力方面有出色表现,可以高效处理中文,并且经过多任务有监督微调和人类反馈训练,可进一步提升性能和准确性,尤其在角色扮演的领域,表现效果尤为突出。
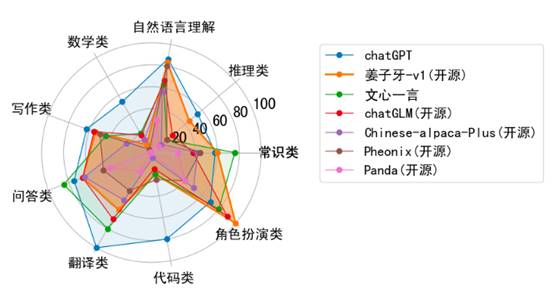
图片来源:https://huggingface.co/IDEA-CCNL/Ziya-LLaMA-13B-v1
写在最后
作为开源模型,姜子牙大模型鼓励开发者和研究者之间的合作和共享,这使得更多的人可以通过领域知识微调,共同改进模型并推动新模型的推出与发展,技术的本质在于应用,ChatLaw(法律大模型)应用法律行业,就是大模型落地垂直业务场景的极佳案例。
UCloud将继续与IDEA等优秀合作伙伴密切合作,致力于完善大模型和算力相结合的MaaS(Model as a service)服务生态,积极推进人工智能技术的发展,为客户提供更多高性能、高可靠性的“算力+模型”解决方案,助力企业实现智能化转型和业务创新,一起迎接大模型时代的机遇和挑战!



