








在大数据基础架构选型时,经常听到的一个说法是――“如果数据规模在TB级可以选择MPP架构的关系型数据库,如果数据规模上升到PB级则应该选择Hadoop”。但事实上MPP架构的关系型数据库与Hadoop的理论基础是极其相似的,都是将运算分布到节点中独立运算后进行结果合并。区别仅仅在于前者跑的是SQL,后者则是MapReduce程序。跑什么其实只是形式而已,是用户使用习惯,相对而言SQL作为数据库领域的事实标准语言使用更加广泛,从而限制住用户快速进入Hadoop大数据时代的步伐。
随着Web2.0、Web3.0、移动互联网、物联网等等事物的兴起,人们创造了更多的数据,收集更多数据成为可能,业务的需求促进了大数据技术包括Hadoop的发展。不少公司都在加快SQL开发,而星环科技则是其中的一员。星环科技CTO孙元浩在2015年第六届中国数据库技术大会(DTCC)上表示,随着Hadoop上SQL性能上及安全容错上的不断提升,Hadoop在未来两三年将会取代MPP,混合架构会逐渐的消失。
作为国内数据库与大数据领域最大规模的技术盛宴,2015年第六届中国数据库技术大会(DTCC)在一场北京近年来最大的沙尘暴中拉开了序幕。4月16日,大会第一天上午,来自星环科技的CTO孙元浩给我们带来《大数据基础技术发展的两大方向和最新研发成果》的主题演讲。
大数据基础技术发展的两大方向是什么?为什么会是这两个?星环科技在这两方面有那些研发突破?为何Hadoop能取代MPP,混合架构会消失?为何星环科技会与众不同,定位基础软件公司?星环的产品策略又是什么呢?带着这些问题,老鱼在会后专访了星环科技CTO孙元浩,就这些问题进行询问和解答。
老鱼:孙总,您好!一直听说你是个富有传奇色彩的人,今天终于见到真人了,先请您跟我们的网友打声招呼,简单介绍下自己和公司产品。
孙元浩:大家好,我是孙元浩,其实我的经历还是比较简单的,大学硕士毕业后加入英特尔,在英特尔工作了10年(曾任英特尔亚太研发有限公司数据中心软件部亚太区CTO)。2013年离开英特尔创业2年,也就是星环科技,从事大数据时代核心平台数据库软件的研发与服务。公司研发团队大多来自知名外企,员工的85%为研发工程师,以博士硕士为主。
我们的产品Transwarp Data Hub (TDH)是基于Hadoop和Spark的分布式内存分析引擎和实时在线大规模计算分析平台,相比开源Hadoop版本有10x~100x倍性能提升,可处理GB到PB级别的数据。星环科技同时提供存储、分析和挖掘大数据的高效数据平台和服务。
老鱼:您在演讲中提到Hadoop技术经过10年的发展,到目前为止还没有被大面积普及的制约因素有2个:SQL技术制约和弹性计算的需求没被得到满足,这2个因素限制了Hadoop的普及,解决这2个问题将成为大数据技术发展的两大方向。Hadoop普及涉及的问题有很多,为什么您觉得解决这2个问题会成为大数据技术发展的方向?能否给我们具体分析下?
孙元浩:这其实是过去几年,我们从市场上观察到的现象,Hadoop还没有被大面积普遍采用,障碍来自两个方面:
1、SQL on Hadoop的技术进展制约了企业原有应用的迁移以及新应用的开发;
2、Hadoop加速Docker化,企业在建设大数据平台或者Data Lake时,往往有多租户资源管控和弹性计算的需求,这些需求现有的YARN或者虚拟化技术没有满足。
第一个方面,过去大家谈大数据,做一些数据挖掘的工作,但实际上企业更多的应用是在结构化数据的处理,主要用的操作语言是SQL,我们发现60%的Hadoop应用是用在SQL统计领域。
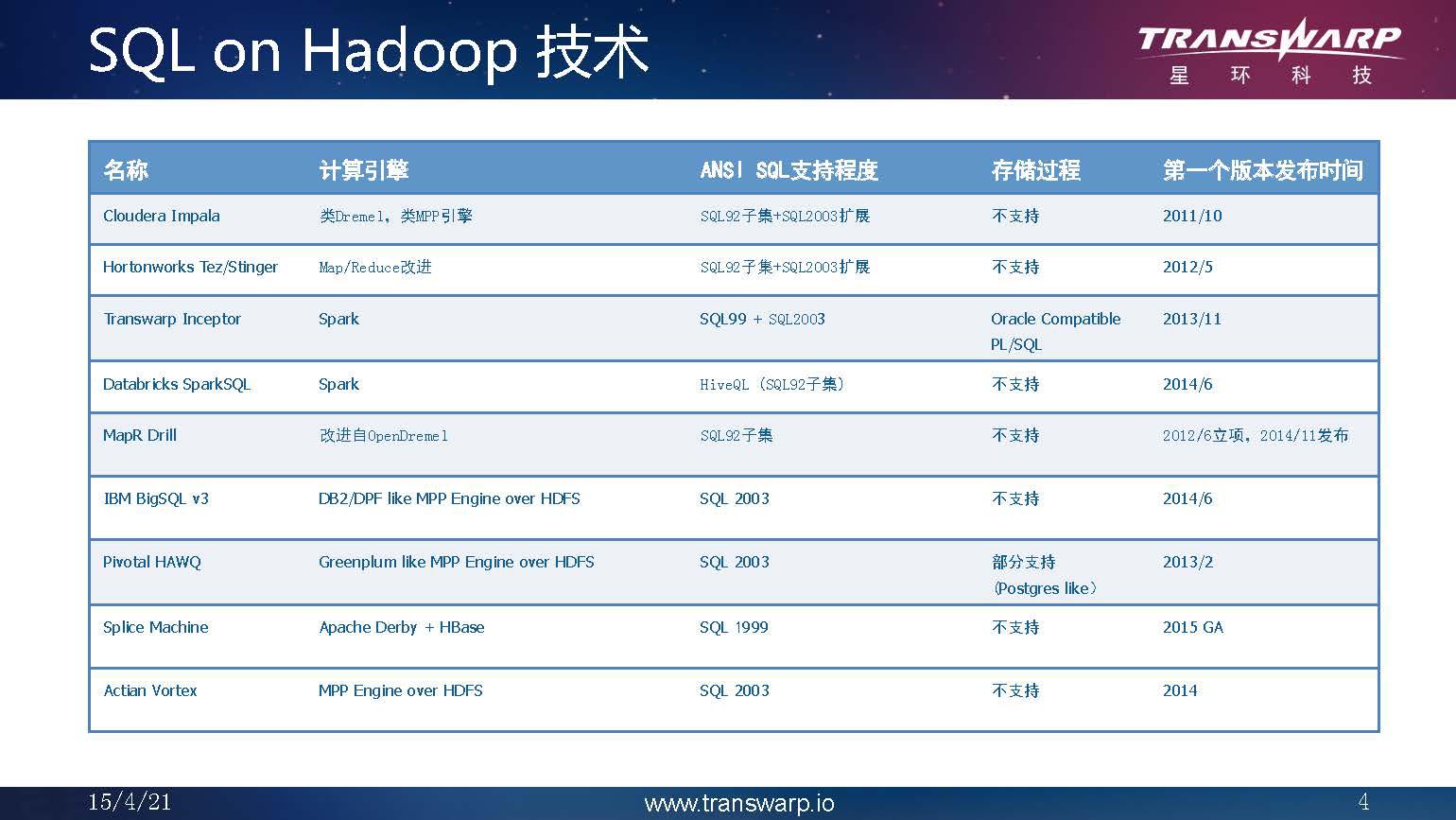
当我们把Hadoop运用到企业中去时,新应用有待验证,老应用其实已经出现了数据量很大,急需用Hadoop来加速的需求,但现在的问题是,客户想迁到Hadoop上,形成效率降低成本,却迁不过来!其中的关键因素是大量客户的SQL极端复杂,这种情况我们在运营商和银行都有发现,银行贷款风控SQL非常复杂,要完成迁移需要太多时间去改造,有些语法甚至没办法改造,因此SQL支持的完整程度比性能更加重要,没有这些语法支持,要想把现有应用迁移到Hadoop上来是不可行的。
SQL作为数据库领域的事实标准语言,相比较用API(如MapReduce API,Spark API等)来构建大数据分析的解决方案有着先天的优势:一是产业链完善,各种报表工具、ETL工具等可以很好的对接;二是用SQL开发有更低的技术门槛;三是能够降低原有系统的迁移成本等。因此,SQL语言也渐渐成为大数据分析的主流技术标准。而要想让SQL用户快速进入Hadoop大数据时代,就必须要解决这个问题。
第二个方面,也来自真实的用户诉求。我们有三分之一以上的客户要求把Hadoop跑在虚拟机上,但每次我们都只能无情的拒绝,因为Hadoop放在虚拟机上,性能瓶颈是非常严重的,稳定性很差,主要原因是因为传统的虚拟机是把一台物理机变成多个虚拟机,CPU负载很低。而虚拟机跑大数据应用, CPU利用往往达到99%,很少有人在虚拟机上把CPU用到99%,这个时候hypervisor就撑不住了,稳定性成为一个大问题,这也就阻碍了用户使用Hadoop第二个大问题。
因此,这2个方向都是我们希望帮助客户解决的,市场非常大,如果把这2个问题解决,我相信Hadoop在使用上就能再上一个量级。
老鱼:孙总,能否在这里给我们介绍下星环针对这2个问题,取得的最新技术研发成果?
孙元浩:其实我们最新技术研发成果都是被客户逼出来的,我们的研发成果是源于用户需求。有客户问我们,我这里有21万2千行的SQL你能不能跑?也客户有30几万行SQL,说你们Hadoop不是很牛吗?试试能不能跑?这迫使我们在2013年组织一个由编译器专家组成的团队,开发了一个Hadoop PL/SQL编译器,当时的目标是选择跟Oracle兼容,先把Oracle用户迁移过来,经过2年的发展,我们星环的Transwarp Inceptor实现了自己的SQL解析执行引擎,可以兼容SQL 99和HiveQL,自动识别语法,因此可以兼容现有的基于Hive开发的应用。由于Transwarp Inceptor完整支持标准的SQL 99标准,传统数据库上运行的业务可以非常方便的迁移到Transwarp Inceptor系统上。此外Transwarp Inceptor支持PL/SQL扩展,传统数据仓库的基于PL/SQL存储过程的应用(如ETL工具)可以非常方便的在Inceptor上并发执行。另外Transwarp Inceptor支持部分SQL 2003标准,如窗口统计功能、安全审计功能等,并对多个行业开发了专门的函数库,因此可以满足多个行业的特性需求。
另外一个相当大的突破,是我们开辟了一个新的产品线TOS(Transwarp Operating System),TOS是为大数据应用量身订做的云操作系统。基于Docker和Kubernetes,TOS支持一键部署TDH,基于优先级的抢占式资源调度和细粒度资源分配,让大数据应用轻松拥抱云服务,不限于跑Hadoop集群,也可以跑传统的数据库业务如MySQL, PostgreSQL, Redis等,解决第二个挑战。这个操作系统正式发布是今年的6月份,目前其实已经提供给客户开始试用了。在国内Docker化的Hadoop系统,我们是领先的。

老鱼:我们经常听到的一个说法,用MPP处理PB级别的、高质量的结构化数据;用Hadoop实现半结构化、非结构化数据处理。这样可同时满足结构化、半结构化和非结构化数据的处理需求。而您今天谈到一个观点,随着SQL在性能上及安全容错上的不断提升Hadoop会取代MPP,混合架构架构会消失!这个观点的依据是什么?
孙元浩:混合架构本身就是一种无奈而折中的选择,同时维护多个系统运维难度非常大。当初,Hadoop的诞生是为了更方便地处理非结构化数据和半结构化数据,但是处理结构化数据的时候功能就显得不够完整。用户还需要使用数据库或者MPP(大规模并行处理)数据库,协助Hadoop处理结构化的数据。另外,Hadoop是为处理几百TB和几PB数据而设计的,但是,当数据量小于10TB的时候,Hadoop的处理性能往往还不如MPP数据库。
随着SQL on Hadoop技术的快速发展,SQL完整程度的大幅提高和性能的提升,我们做的第一个判断是混合架构会逐渐的消失,过去MPP数据库有三个优势,第一个SQL支持完整,现在我们的SQL支持程度已经接近MPP数据库;第二个它比Hadoop性能高,但我们看到现在Hadoop性能可以超过MPP若干倍。第三个优势就是说它上面的BI工具,外延工具非常全,传统的BI厂商都已经转向Hadoop,Hadoop系统的BI工具也越来越丰富,还有一些新兴的创业公司在Hadoop上开发全新的BI工具,这些工具原生支持Hadoop,从这个角度来讲Hadoop的生态系统将很快超越传统MPP数据库。
我们觉得在未来一年两年之内,Hadoop将逐渐取代MPP数据库,大家不需要用混合架构,不需要在不同数据库之间实现迁移了。有人说我MPP也在迁移,慢慢向Hadoop靠拢,这也是事实,整个MPP的数据库在慢慢消失,完全走到Hadoop上面来。我们希望最后结果就是数据全部放在Hadoop上,不管数据在几个GB级别还是10个PB级别,都可以在Hadoop上处理,真正做到无限的线性扩展。
老鱼:星环科技我理解是一个做基础软件(数据库)的公司,不知道这么理解对不对?为什么当初是这个定位?
孙元浩:你这个问题很好,现在有很多客户也问我同样的问题,客户把我们定位成一个大数据应用和解决方案的公司,是因为国内大部分大数据公司都是这种类型,其实我们定位是大数据平台,是做基础软件的。为什么要做基础软件?因为我们看到一个明显的技术演进趋势,从单机计算,多核计算到分布式计算,这个趋势是技术的潮流,是一次至下而上的架构革命,这种机会可能10年或者20年才能碰到一次,而这一领域正是我们擅长的,所以我们准备投入到这个领域。在中国,用户数众多,除了美国,中国企业的数据量普遍要多于国外企业一个数量级;中国企业的应用场景也非常复杂,很少有国外产品不经修改在中国能够不出故障地运行,因此中国也是需要这样一个大数据的基础软件公司,所以我们认为在中国市场发展的机会很大,这也我们在基础软件发力的原因。我们在中国也有很多的合作伙伴,开发着各种应用,我们也在建立生态系统。
综上所述,第一,技术趋势在向这个领域发展。第二,市场环境对我们有利。第三、我们创始人和团队的技术储备和经验在这个领域很深厚。这就是我们创立星环科技的初衷,致力于提供优秀的大数据基础软件,来解决这些问题。
老鱼:做基础软件是一件非常难的事情,资金、人才、技术、规模等等要求都非常高,您在创业的是否有考虑过这些问题?
孙元浩:这也是个很好的问题,我们有思想准备。做基础软件确实是一个投入非常大的事情,动辄上千万上亿投入,才能把产品做好。如果我们去做应用,在大数据应用领域我们没有太大的创新点,也没办法去区别于其他公司,而基础软件是我们擅长的。
我们的目标并不是追逐短期内获益或者说是个人财富短期迅速增长,我们目标放的更长远,那就是要把这个事情做好。星环的大部分人都是从外企走出来的,大家放弃了高薪,唯一的目的就是想把这个事业做好。
做基础软件,人才一直是比较难解决的问题,不过创业型公司跟大型外企和互联网公司相比,我认为有几点还是比较有吸引力:
第一、我们的工作是创新的前沿的,比较挑战性,这对技术高手是比较有吸引力的。
第二、员工激励,我们是全员持股,每个人都有公司期权,这跟在外企打工有很大不同,大家都是平等的,都是指挥官,大家一起奋斗。
第三,国内创业环境氛围很好,国家鼓励创新创业,对于人才的加入创造了一个有利的环境。
当然除此之外,招聘依然还是个老大难的问题,因此我们一方面与招聘机构合作,另一方面也自己在培养新员工,引进一些技术高手。
老鱼:从架构图中,我看到星环对Spark, Shark, Hbase等Hadoop生态圈的组件都进行很多的改造和优化,也常关注国内外大数据的最新技术动态并且考虑如何加入到产品中来,星环新增功能和产品功能改造将会依据一个什么样的规则?
孙元浩:我们的产品策略,得从我们的产品架构图上讲起。如下图

Hadoop这层我们会与社区同步,并向社区反馈贡献。在Hadoop之上这层,我们会有3大组件Transwarp Hyperbase, Transwarp Stream,Transwarp Inceptor,这3个组件我们定位成自己的产品,我们会独立开发和发展,这块产品启用标准的SQL,或者开放API,这是个分割线。Hadoop生态系统的组件我们保证和开源版本全兼容的,包含Spark也会跟接口做兼容性测试。





