








数据防护—战胜来自“未知”的恐惧
文|高宁@浅黑科技
假如把互联网形容成一个巨人,那么在大数据时代以前,恐怕这头巨人还在匍匐前进。
大约10年以前,大数据的崛起打通了巨人的任督二脉。
短短10年,大数据催动着巨人迈开步子急速奔跑。但诸多经脉症结隐于血肉之下,让巨人的脚步有些踉跄。
在我看来,最深层的恐惧来自于未知。
想象一下,你身披铠甲、手握长矛警惕提防着暗处的敌人,横空飞来的弩箭瞄准铠甲的接缝,精准的刺伤了你裸露在外的皮肤,剧痛过后你勉强回身,敌人却再次隐入黑暗之中。
大数据防护经常处于这种恐惧中。
为了探清这些威胁和可能的解决方法,3月底的一天,我参加了瀚思科技的见面会。

(画面中的男子是瀚思VP周奕)
周奕告诉我,防守的前提是摸清敌人进攻的路数。我想,真正的高手过招大抵如此。
悄然变化的数据威胁
“放之四海皆准的攻击方法已经越来越少了”,周奕如是说。
我们不妨把事情讲的更严重些,当大家都认同数据价值的时候,数据就像一块流油的肥肉,周遭必然虎狼环伺。
而伴随着数据价值的飙升,类似勒索病毒这种广撒网的攻击方式变少了,取而代之的是放长线钓大鱼。
数据威胁的方式为何发生变化?
或许我们能从勒索病毒Wannacry中窥见一斑。
2017年影响最大的Wannacry数据勒索事件,据统计,全球近20w台电脑中招,勒索赎金每台300美元,听起来肯定赚了个盆满钵满。但事后统计,总共收到比特币赎金11w美元。
对于一个全球爆发的病毒来说,这点钱实在不多,更有趣的是赎金是用比特币支付的,因为怕被追踪到,攻击者实际上一分钱都没敢提出来用。
所以,折腾了半天,攻击者一分钱也没拿到。
值得揣摩一下,Wannacry为什么没有赚到钱?
恐怕与技术手段无关,攻击者选错了目标,没有威胁到太高价值的数据。
换句话说,谁也不会花大价钱赎硬盘里的小黄片。
黑产的触觉十分灵敏,他们的目标很快转向了更具价值的企业数据。
与黑产长期的斗争让周奕十分了解他的对手。
“为了拿下高价的企业数据,黑产做了更多的功课”
有趣的是,虽然我们经常将数据泄露与黑客大战联系起来,但现实中的泄露案件要猥琐的多。
举个例子,大多数时候黑产想要获取机密数据,不必大费周章的攻破服务器,只要偷到登录权限就可以。
而掌握核心数据的往往是管理层,这意味着攻击会变得目的性很强,攻击者会花费很多时间在高管身上做“社工”,目的可能只是盗取邮箱登录权限。
而我们不得不承认大家都不是很重视这些信息的防护。
以有心算无心,中招者自然遍地都是。
企业的担忧是什么
事实上,企业在数据防护上是花了大价钱的。
想象一下,你的公司刚刚做了一个重大的战略决策转眼就被竞争对手获悉,或者某项研发的关键数据悄无声息的流向黑市。利益损失自然不必多提,严重者会对公司造成毁灭性的打击。
而传统的防护机制,无外乎网络防火墙、内网隔离,先不论技术上是否过关,恐怕这类防护机制从理念上就与现实情况脱了节。

(美国某权威机构关于数据泄露的统计数据)
从这组数据不难发现,透过传统网络攻击获取高管或特权账号,从而造成数据泄露的情况,只占整体的百分之十。
这意味着企业的传统防护机制并不能有效防止数据泄露。
换句话说,最严重的威胁往往来自内部人员的疏漏,或者是自己人的恶意行为。
所以摆在企业面前的问题不仅仅是如何抬高防火墙,而是如何分辨恶意行为。
了解了这些风险,就不难理解企业为什么会动辄花费百万购置数据防护系统。
那么,现有的防护系统,也就是传统的DLP数据泄漏防护系统(以下简称DLP),能否应付复杂的威胁呢?
上文已经提过,数据威胁的攻击手段五花八门,外部网络攻击再加上内部人员的疏漏、恶意窃取。
而DLP作为一个主要用于加密和审计的系统,应付这些显得捉襟见肘。
最主要的问题在于,DLP的安全策略相对死板。
对企业来说,提高DLP门槛会增加误报率影响企业效率,而降低门槛相应的就会提高风险。
更为关键的是DLP本质上还是在抵御外来攻击,对于内部监督的意义并不大。
还有另一个层面,当DLP系统落地到现实的防护场景中,企业往往要面对大量的误报,从而增加了运维的难度。
显而易见,企业更关心的是,如何在海量DLP告警中,挖出那些真正需要立即处理的数据泄露事件。
不得不说,传统DLP防护还做不到这一步。
数据防护的多维武器
周奕引用了一句颇具禅意的话,这是数据防护市场最真实的需求。
“洞悉已知,侦测未知”
说白了,企业只想要这两个东西,
洞悉已知:帮我看见和梳理已知的安全问题。
侦测未知:告诉我未知的安全风险。
周奕举了一个生动的例子。
他说企业目前需要的是一份综合“体检报告”。
简而言之,DLP产品会提供给你一份体检报告,你能清楚地看到血常规、大小三项这些数据是不是在合理的范围内。
然后给出一个结论:目前你没有糖尿病、心脏病这些已知疾病。
但是你无法获知身体是否存在其他风险。比如,虽然各项指标都正常,我还是偶尔会头疼,是不是有些未知的疾病呢?
这时,数据防护需要的是了解对手的攻击路数,只有这样才能做到有的放矢。
周奕告诉我。
瀚思的策略是:将机器学习用于异常行为监测,将异常行为监测与DLP结合起来达到数据防护的目的。
简而言之,数据安全面临的威胁可能是多方面的,但是万变不离其宗,想要窃取数据就一定会有异常的操作。
这有些类似警察破案,想要追踪一个凶手就要从凶手的行为模式上寻找蛛丝马迹。
瀚思UBA(用户行为分析系统)是个很好的例子,
UBA的作用是什么?
首先是定位行为异常人群,然后分析用户有没有异常行为,也就是有没有执行敏感数据外流的行为。
如此一来,UBA能够准确定位数据泄露,有效解决了传统DLP系统误报的问题。
并且能够深挖出异常行为的动机,也就是窃取数据。
这听起来很神,但是假如了解UBA的工作机制,会发现其中逻辑并不复杂。
其实数据防护首要目标应该是防止数据外流,至于判断内部人员的属性都是后话(无数间谍片告诉我们那太难了)。
因此,如何判断异常行为变得非常重要。
周奕简单介绍了UBA的工作机制。
“UBA会根据个人或部门的行为基线定位异常人群”
什么是行为基线?UBA又如何完成定位呢?
周奕解释。
在部门内,每个员工登录服务器的时间、浏览的内容等等实际上是比较固定的。
把这些数据整合起来就会形成一个标准的行为基线,而一旦某员工一旦出现异常操作,他的行为就会与标准行为基线出现偏离。
举两个简单的例子。
其一,部门人员登录服务器的时间出现偏差。
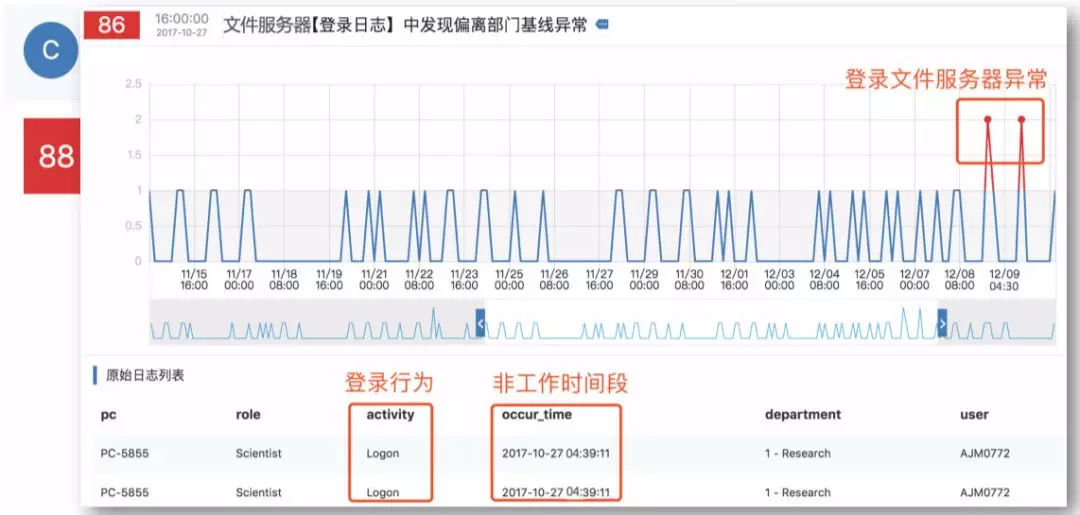
上图中的红线部分表明,用户在异常时间段登录了服务器,UBA会接收到异常行为预警,当然这可能只是个意外,并不能说明什么。
但是,假如同时这名用户访问了本不该访问的东西,事情就变得敏感了。
其二,敏感数据的访问出现偏差。
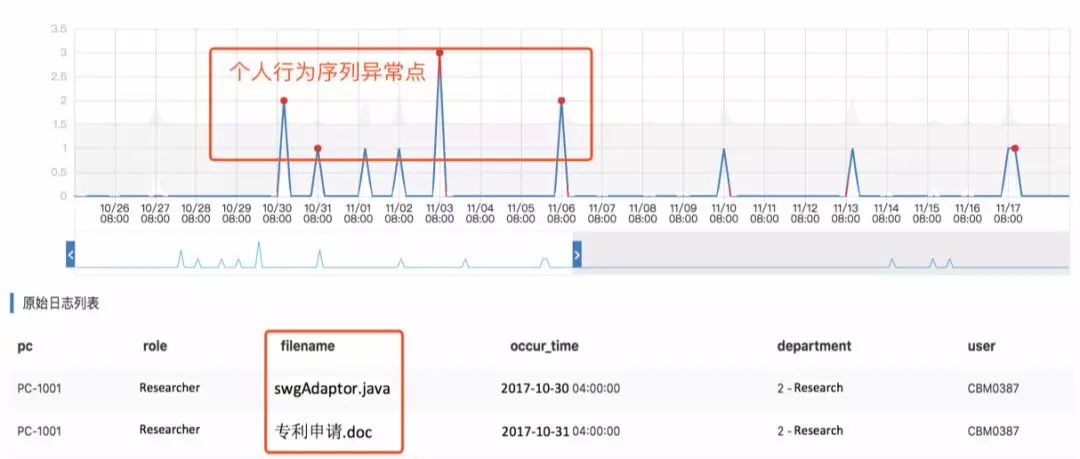
很显然,一名用户在不正常的时间段登录服务器可能代表不了什么,但是同时又访问了敏感文件,这就很值得警惕了。
假如这时这名用户又拷贝了文件,那么很明显,窃取数据的意图完全暴露了。
这时UBA系统就会对其做出内部威胁判断,发出需要立即响应的最高优先级告警。
不难发现,在UBA的整个检测和治理流程中,通过行为基线比较从而发现异常行为是最重要的方法。
值得注意的是瀚思开放了维度的选择权,也就是说企业可以自行选择“降维”还是“升维”,区别在于更复杂的维度会锻炼AI形成更精准的防护体系。
一点思考
跟随周奕的思路,我大概了解了瀚思UBA的技术原理。
除去技术上的创新,我还发现,在AI的应用理念上UBA是一个十分具有科幻感的东西。
打个比方,几年前的AI技术其实主要依赖程序员的数据灌输。
假如你想要制作一个智能翻译工具,首先要把数据全部输入进程序里,AI对照数据库中的信息才能给出答案。
这个时期的AI就像是一个刚出生的婴儿,要手把手的教,处在“全监督”的学习状态。
UBA系统中的AI应用一定程度上已经具备了自主学习的能力,自发的从病毒样本和异常检测中不断拓宽知识面。
在这个层面对AI的应用俨然有了三岁孩子的智力,或者说人工智能进入了“半监督”的学习状态。
我不确定对于解决潜在数据威胁,将深度学习用于数据防护是不是唯一路径。
有一点是我可以肯定的,数据的价值只会在未来越发凸显,它会成为人工智能深度学习的养料,而不论对用户自身还是企业来讲,大数据都是需要得到保护的资产。
当然,这也意味着在互联网巨人奔跑的的时候,觊觎大数据价值的宵小会越来越多。他们会把灵敏的触角伸向每一个脆弱的关节,而防守力量往往要被刺痛后才会奋起直追。
与此同时。
……
在某企业服务器中,蛰伏的爬虫迅速撑开了猩红的眼睛。
在过去几个月中它不断的重复动作,休眠…苏醒…爬动…窃取。
眼看关键数据近在眼前,它再也按捺不住内心的狂喜,伸出毫米粗细的触角。
数据经由触角进入爬虫的身体,伴随着一阵白光,主人将接收到最后的战利品。
它仿佛看到了主人迎接胜利的微笑……
“啪……”
爬虫生前的最后一眼,它看到一个机器人拎着一把沾满自己鲜血的苍蝇拍。





