3.2 Storm
Storm通常被比作“实时的Hadoop”,是Twitter开发的实时、分布式以及具备高容错计算系统,可以简单、可靠地处理大量数据流,用户可以采用任意编程语言来开发应用。
在Storm中,一个用于实时计算的图状结构称之为拓扑(topology),拓扑提交到集群,由集群中的主控节点分发代码,分配任务到工作节点执行。一个拓扑中包括spout和bolt两种角色,其中spout发送消息,负责将数据流以tuple元组的形式发送出去;而bolt则负责转换这些数据流,在bolt中可以完成映射map、过滤filter等操作,bolt自身也可以随机将数据发送给其他bolt。
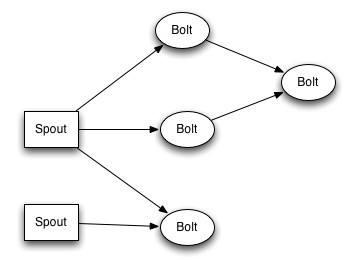
图4 Storm数据流动
Storm能将数据在不同的bolt中流动、移动数据,真正实现流式处理,易于扩展,灵活性强,高度专注于流式处理。Storm在事件处理与增量计算方面表现突出,能够以实时方式根据不断变化的参数对数据流进行处理。
3.3 Kafka Stream
Kafka Stream是Apache Kafka开源项目的一个组成部分,是一个功能强大、易于使用的库,它使得Apache Kafka拥有流处理的能力。
Kafka Stream是轻量级的流计算类库,除了Apache Kafka之外没有任何外部依赖,可以在任何Java程序中使用,使用Kafka作为内部消息通讯存储介质,因此不需要为流处理需求额外部署一个集群。
Kafka Stream入门简单,并且不依赖其他组件,非常容易部署,支持容错的本地状态,延迟低,非常适合一些轻量级流处理的场景。
3.4 Flink
Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,同时支持批处理以及流处理,主要针对流数据,将批数据视为流数据的一个极限特例。
Flink核心是一个流式的数据流执行引擎,它提供了数据分布、数据通信以及容错机制等功能。流执行引擎之上,Flink提供了更高层次的API以便用户使用。Flink还针对某些领域提供了领域库,例如Flink ML、Flink的机器学习库等。
Flink适合有极高流处理需求,并有少量批处理任务的场景。该技术可兼容原生Storm和Hadoop程序,可在YARN管理的集群上运行。目前Flink最大的局限之一是在社区活跃度方面,该项目的大规模部署尚不如其他处理框架那么常见。
3.5 PipeLineDB
PipelineDB是基于PostgreSQL的一个流式计算数据库,效率非常高,通过SQL对数据流做操作,并把操作结果储存起来。其基本过程是:创建PipelineDB Stream、编写SQL、对Stream做操作、操作结果被保存到continuous view。
PipelineDB特点是可以只使用SQL进行流式处理,不需要代码,可以高效可持续自动处理流式数据,只存储处理后的数据,因此非常适合流式数据处理,例如网站流量统计、网页的浏览统计等。
3.6 架构对比
上文提到的5种流式处理框架对比如表1所示:
表1 流式框架对比
 高层
高层 访谈
访谈

 观点
观点
