图6 4G DPI实时统计方案图
数据源是gzip压缩文件,因为flume原生不支持.gz或.tar.gz文件格式,所以修改了Flume底层代码,实现对压缩文件的处理,省去了解压时间。Flume采集文件时以用户手机号码作为分区的key,将同一号码的数据分到同一分区,便于去重。通过Kafka集群管理工具,Kafka Manager[17]可以很好地监测Kafka集群的状态。Kafka集群生产者如图7所示:
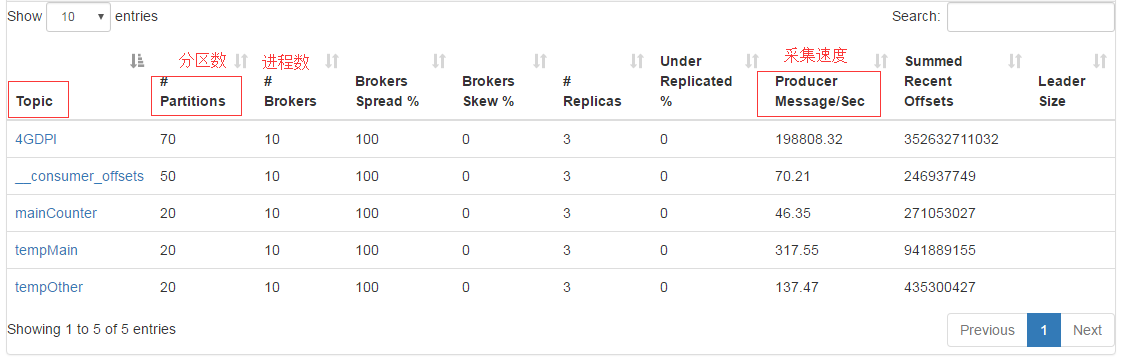
图7 Kafka集群生产者
Kafka Stream消费4GDPI的数据,并行处理。在程序里设置不同的计数器,所有数据都经过这些计数器处理,为了解决去重问题,引入了布隆过滤,虽然有一定的误判率,但是还是能比较好的完成去重,同时保证系统的性能。同样消费者也可以通过Kafka Manager进行管理,可以直观观察到消费者的落后程度。
为了满足不同的输出要求,程序设置了三种输出供选择。粒度为天的数据将会写到MySQL作为备份,针对热点区域的监控数据将会输出到Redis,同时,为了方便管理以及数据呈现,还采用了ELK框架(ElasticSearch+Logstash+Kibana),将所有数据传到Kibana做前端展示。Kibana界面如图8所示:

图8 Kibana界面
5 实践及分析
5.1 部署实践
上述两个系统均已应用在实际的生产中,均有不错的表现,能够满足任务需求,并且已经稳定运行。
宽带DPI处理项目有2台采集机、1台AAA服务器及5台Kafka机器。采集机每台每秒产生115 MB数据,两台1.8 G流量。采集机写Kafka 33万条/秒,Kafka Stream写Kafka 22万条/秒,清洗率(清洗工作把诸如图片、视频及js请求等与业务无关的DPI信息去掉)为33%。Kafka Stream落后处理稳定在500万数据,延迟处理在15 s之内,Flume写HDFS落后保持在100万左右,5 s内的延迟。宽带DPI处理项目性能如图9所示:
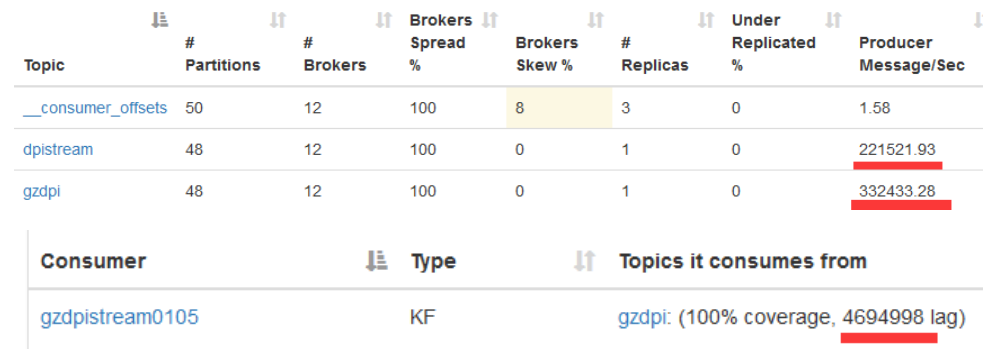
图9 宽带DPI处理项目性能
4G DPI实时统计项目共6台机器,1台为Flume采集机,其余5台部署Kafka、Kafka Stream及ELK。采集机写Kafka一般为10万条/秒,峰值可达到25万条/秒。ElasticSearch集群一共8个实例,每个实例配置2 G内存。目前集群有13亿条数据,占361 G空间。通过Logstash导入数据到ElasticSearch峰值可以达到8~9万条/秒。Kafka Stream处理数据落后在10 s内,Logstash写ElasticSearch落后在5 s内,如图10所示。目前4G DPI实时统计项目日均处理文件超过15 000个,大小达到1.6 T,日均处理记录数超过100亿。

 高层
高层 访谈
访谈

 观点
观点
