








一开始Google想撇清关系,对外声明这种仇恨言论虽然出现在搜索结果里,但并不代表Google的立场。而《卫报》记者随即发现,只要在Google的广告服务AdWords上付费,就能改变置顶的网站。
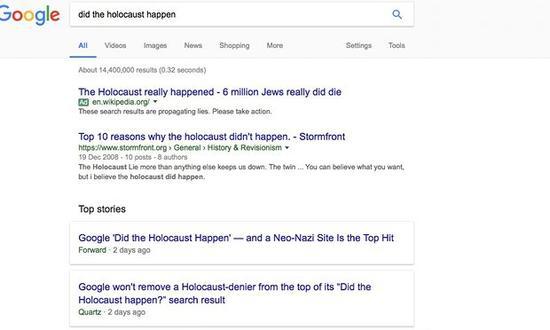
《卫报》记者付费后改变了搜索结果的排序,她自创的条目“The Holocaust really happened”以广告的形式被置顶。
在越来越大的舆论压力之下,27日,经过紧急修改,现在Google已经完全移除了“大屠杀没有发生”这种搜索结果和相关的问题链接。先不谈技术公司是否需要像媒体一样对平台上的内容负责,从这件事就可以看出,连谷歌的的算法都不完美。
虽然Google否认他们奖励那些点击率高的网站,但他们也并未更多解释目前使用的算法。业界权威建议,Google应该尽可能增加搜索结果排名的透明度,并利用人工复查等方式弥补算法现有的缺陷。
对抗假新闻,我们还能做什么?
Dean Pomerleau现任卡耐基梅隆大学的客座教授。这位在1989年就造出了自动驾驶汽车,并预判到人工智能火热应用前景的AI专家也深受假新闻困扰,于是,他始发了一项名为#FakeNewsChallenge的竞赛,希望机器学习和人工智能界的好手能够开发一种鉴别假新闻,并将之移除的算法。
他个人出资1000美元作为获胜者的奖金,同样出资1000美金的还有亚马逊Echo声音识别系统的开发者Delip Rao。各国好手们纷纷组队参赛,在接下来的6个月之内将相竞用神经网络系统等机器深度学习方法来创建对抗假新闻的算法。
但这样的尝试不一定会成功。
假新闻从出生以来,从未被打败。最早的假新闻可以追溯到1475年的意大利,它存在的目的,就是煽风点火,传播歧视言论和固化偏见,并引发社会暴力行为。1439年古登报堡发明了铅字打印技术后,假新闻随着报纸的兴起而盛行。很多我们耳熟能详的极端历史事件都与假新闻扯不开,比如中世纪的焚烧女巫、海怪传说,甚至是纳粹的反犹歧视宣传,也借用了15世纪“犹太人在祭祀仪式上喝幼童的血”的假新闻。
与假新闻的战争,是人类理性和懒散愚昧本能之间的战争,理智一松懈,假新闻就会趁虚而入。
Delip Rao的计划是,着手建立一个庞大的假新闻数据库,不断收集新数据,训练算法鉴别假新闻,当算法得到升级,它找寻判别假新闻的能力随之增强,越来越多的假新闻被加入数据库中,形成一种正向循环。
就像斯坦福大学建的ImageNet图片数据库,神经网络通过大量数据分析,现已能分辨电子图片中的人脸。但这也有难度,因为假新闻的判定本身需要大量精力与时间。它没有唯一的判定标准,有些新闻似是而非,不实比例可大可小,在辨别消息真假之前,读者不仅要对新闻来源和文中涉及到的历史地理文化背景有所了解,还需要理解文本语义修辞,别错把反话看成陈述。
Dean Pomerleau对此也早有认识。他接受采访时表示,让机器判断虚假信息,相当于要求它们达到受过较高水平教育的人的智能水平,这在短期看来是不会实现的。因此,他们旨在开发的算法无法取代人类,但能帮助人类,快速准确地排查假新闻。
数据时代,假新闻的产生与流量、点击率和利润紧密相关,而科技公司、社交媒体、传统媒体、各种形态的新闻聚合平台和公众即将共同面对的,是一场对抗假新闻的硬仗。算法目前还没有能力检测新闻的真假,而如今的媒体生态下, 或许最合适的方式还是人类与机器协同工作。(本文首发钛媒体,记者/元婕)





