








●PG检测到触发XOFF水线,到构造PFC帧发出的时间(这里主要跟配置的检测精度以及平均队列算法相关,固定配置是固定值)
●上游收到PFC Pause帧,到停止队列转发的时间(主要跟芯片处理性能有关系,交换芯片实际上是固定值)
●PFC Pause帧在链路上的传输时间(跟AOC线缆/光纤距离成正比)
●队列暂停发送后链路中报文的传输时间(跟AOC线缆/光纤距离成正比)
因此Headroom所需要的缓存大小,我们可以根据组网的架构,以及流量模型测算得出。以100米光纤线 + 100G光模块,缓存64字节小包,计算出所需的Headroom大小是408个cell(cell是缓存管理的最小单元,一个报文会占用1个或者多个cell),实际测试数据也吻合。当然,考虑一定的冗余性,Headroom设置建议比理论值稍大。
RDMA网络实践
锐捷网络在研发中心搭建了模拟真实业务的RDMA网络,架构如下:
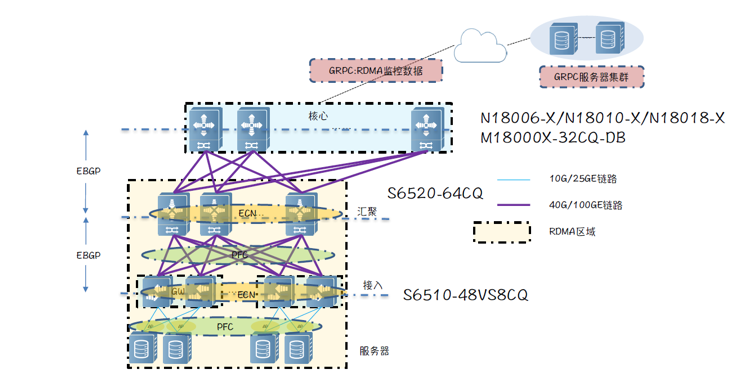
▲锐捷网络RDMA组网架构
●组网模型:大核心三级组网架构,核心采用高密100G线卡;
●POD内:Spine采用提供64个100G接口的 BOX设备,Leaf采用提供48个25G接口+8个100G接口的BOX设备;
●Leaf作为服务器网关,支持和服务器间基于PFC流控(识别报文的DSCP并进行PG映射),同时支持拥塞ECN标记;
●RDMA仅运行于POD内部,不存在跨POD的RDMA流量,因此核心无需感知RDMA流量;
●为了避免拥塞丢包,需要在Leaf与Spine之间部署PFC流控技术,同时Spine设备也需要支持基于拥塞的ECN标记;
●Leaf和Spine设备支持PFC流控帧统计、ECN标记统计、拥塞丢包统计、基于队列的拥塞统计等,并支持将统计信息通过gRPC同步到远端gRPC服务器。
写在最后
锐捷网络在研发中心同样搭建了模拟真实业务的浸泡组网环境(包括RG-S6510、RG-S6520、RG-N18000-X系列25G/100G网络设备、大型测试仪、25G服务器)。在叠加了多种业务模型,并进行了长时间浸泡测试后,我们对于RDMA网络的MMU水线设置已有一些推荐的经验值。此外,在RDMA网络中,还存在一些部署难点,比如多级网络中 PFC风暴、死锁问题、ECN水线设计复杂问题等。对于这些问题,锐捷网络也有一些研究和积累,期待与大家共同探讨。
本期作者:颜晓波
锐捷网络互联网系统部行业咨询
感谢您关注锐捷网络技术干货文章!现诚邀您参与有奖调研,您宝贵的意见和建议将帮助我们在技术探索与分享上持续精进。





