








随着深度神经网络的持续改进和成长,面对日益增长的计算需求,相应的硬件创新也迫在眉睫。
深度学习是人工智能(AI)近期发展的前沿阵地。它涉及到灵感来源于生物神经网络的一系列机器学习算法,可用于在巨量数据中寻找某些模式。通过这些深度神经网络,诸如语音和视觉识别等领域得到了大幅发展;以它们为基础的计算机程序在一些特定任务中展示了超越人类的能力。

相变存储器的二维阵列。来源:IBM研究院
这一点在AlphaGo身上得到了淋漓尽致的展示。这个由伦敦DeepMind团队开发的程序,2016年3月在一场5回合的比赛中击败了围棋世界冠军李世乭,比分为4比1。现在,AlphaGo唯一的对手只剩下自身的改进版。2017年10月,DeepMind团队发布了一款升级版本——AlphaGo Zero——它应用了强化学习,并且只通过自己和自己对弈进行训练。而AlphaGo的能力则建立在对人类专业棋手数百万步走法的非监督式学习。结果,AlphaGo Zero以100回合全胜的战绩战胜了击败过李世乭的AlphaGo。
深度神经网络涉及多层由数字化的‘神经突触’连接的‘神经元’。利用大量数据以及目标任务的正确答案进行训练后,神经元之间连接的强度或者说权重得到不断调整,直到最上层网络给出正确的结果。完成训练的网络配以训练中得到的连接权重再被应用到全新数据中——这一步被称为推断。
深度神经网络近期的成功既得益于算法和网络架构的进步,也得益于获取巨量数据变得日趋容易,以及高性能计算机持续发展。当前,具备一流运算精度的深度神经网络的运算量相当大。史弋宇及其同事在《自然-电子学》上发表了一篇Perspective文章(https://go.nature.com/2lWHPww),他们在文中指出,这代表了深度神经网络面临的新挑战,特别是当它们被应用于空间和电池容量有限的手机以及诸如智能传感器、穿戴设备等嵌入式产品时。
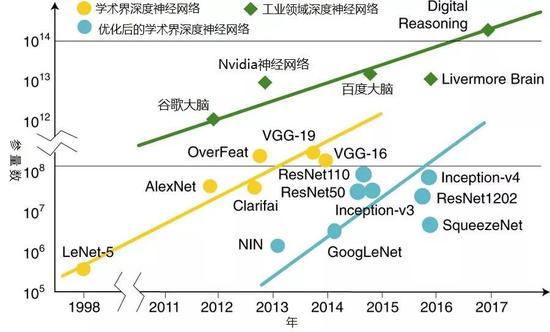
图1:前沿深度神经网络的迭代。深度神经网络的参数量呈现指数式增长。Y轴为对数坐标。
来自美国圣母大学、加州大学洛杉矶分校和中国华中科技大学的研究团队考察了深度神经网络的精度和规模方面的数据,以及不同硬件平台的运算性能。他们指出,深度神经网络应用于设备端推断(在嵌入式平台端执行的推断)的迭代速度和CMOS技术的迭代速度存在差距——而且这个差距在增大。当深度神经网络变得更加精确,它们的尺度(层数、参数量、运算量)显著扩大。
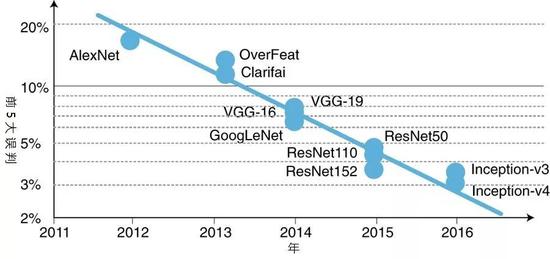
图2:ImageNet图像分类竞赛中明星深度神经网络的前5大误判比率。前5大误判的比率随时间呈指数式下降。Y轴为对数坐标。
但是,正如史弋宇及其同事所述,典型的硬件平台——图形处理单元(GPU)、现场可编程门阵列(FPGA)以及专用集成电路(ASIC)——其计算性能的提升跟不上前沿深度神经网络的设计需求。类似的,承载这些网络的硬件平台的存储器功耗也跟不上网络尺度的增长。





