








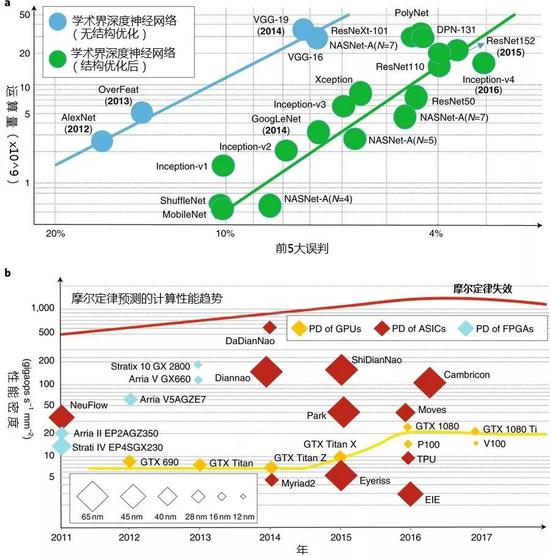
图3:运算量与性能密度之间的差距。a, 运算量对比ImageNet图像分类竞赛中领先的深度神经网络的前5大误判比率。b, 领先的GPU、ASIC和FPGA硬件平台性能密度。为匹配所需运算量,简单增加芯片面积并不可行。各年只标示了夺冠的深度神经网络。Y轴为对数坐标。
史弋宇及其同事指出,“CMOS技术的迭代对于日益增长的计算强度和功耗方面的需求并没有提供足够的支撑,因此需要在架构、电路和器件上加以创新。”基于此,他们继续检验了结合不同架构和算法创新来弥补上述差距的可行性。
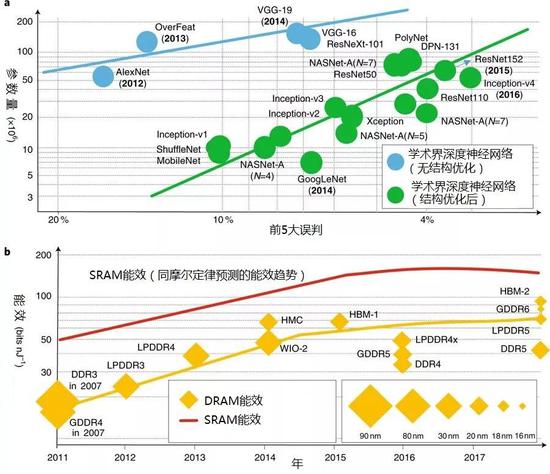
图4:内存访问量和内存能效之间存在差距。a, 参数量(与内存访问量高度相关)对比各年ImageNet图像分类竞赛中领先的深度神经网络的前5大误判比率。b, 主流存储技术的内存能效。内存能效在有限能量预算下将无法支持日益增长的内存访问量。各年只标示了夺冠的深度神经网络。Y轴为对数坐标。
一种方式是放弃传统的,即存储单元和计算单元物理上分离的冯·诺依曼计算架构,比如纳米级电阻式存储器(忆阻器件)能够即用于计算又用于存储。但器件的应变能力仍然是个问题,限制了运算所需精度。
在本期《自然-电子学》的另一篇文章中(https://go.nature.com/2IZ9VAq),来自苏黎世IBM研究院和苏黎世联邦理工学院的Manuel Le Gallo及其同事表明,综合利用电阻式存储器的内存内运算以及传统数字运算,或许能解决这个问题。这里的内存内运算单元,具体来说是一组相变存储器的二维阵列,它们承载主要的计算任务,而传统计算单元则迭代提升解算精度。
Le Gallo及其同事通过解算线性方程组,展示了上述被他们称为“混合精度内存内运算”方案的性能。这种方案之前也被用于训练深度神经网络。
为AI应用开发专用器件和芯片的发展前景也已引起芯片初创公司的兴趣。今年早些时候,据《纽约时报》报道,目前至少有45家初创公司在开发此类芯片,而风险投资者去年在芯片初创公司中的投资超过15亿美元,几乎是两年前投资数额的两倍。
这种技术的潜力不可小觑,学术界和产业界的研究人员正在响应机器学习和AI对硬件提出的挑战——以及随之而来的机遇。





