作者:Stephan Ewen (Apache Flink最早的创建者之一)
整理:秦江杰
本文整理自Stephan Ewen在Flink Forward China 2018 上的演讲《Stream Processing takes on Everything》。

大家好,今天我的演讲主题看似比较激进:流处理解决所有问题。从某种程度上来说,你可以认为这个演讲是之前晓伟对Flink未来(详情参见上一篇文章:Apache Flink®- 重新定义计算)描述的一个继续。很多人可能对Flink还是停留在最初的认知,觉得Flink是一个流处理引擎,实际上Flink可以做很多其他的工作,比如批处理,比如应用程序。接下来我会简单的说明我对Flink功能的观点,然后我会深入介绍一个特别领域的应用和事件处理场景。这个场景乍看起来不是一个流处理的使用场景,但是在我看来,实际上它就是一个很有趣的流处理使用场景。
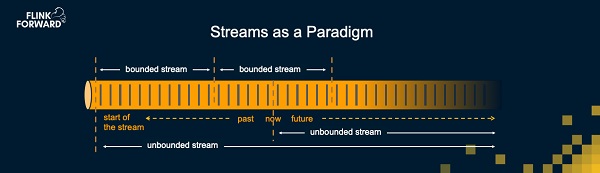
上图对为什么流处理可以处理一切作出诠释,将数据看做流是一个自然而又十分强大的想法。大部分数据的产生过程都是随时间生成的流,比如一个Petabyte的数据不会凭空产生。这些数据通常都是一些事件的积累,比如支付、将商品放入购物车,网页浏览,传感器采样输出。
基于数据是流的想法,我们对数据处理可以有相应的理解。比如将过去的历史数据看做是一个截止到某一时刻的有限的流,或是将一个实时处理应用看成是从某一个时刻开始处理未来到达的数据。可能在未来某个时刻它会停止,那么它就变成了处理从开始时刻到停止时刻的有限数据的批处理。当然,它也有可能一直运行下去,不断处理新到达的数据。这个对数据的重要理解方式非常强大,基于这一理解,Flink可以支持整个数据处理范畴内的所有场景。

最广为人知的Flink使用场景是流分析、连续处理(或者说渐进式处理),这些场景中Flink实时或者近实时的处理数据,或者采集之前提到的历史数据并且连续的对这些事件进行计算。晓伟在之前的演讲中提到一个非常好的例子来说明怎么样通过对Flink进行一些优化,进而可以针对有限数据集做一些特别的处理,这使得Flink能够很好的支持批处理的场景,从性能上来说能够与最先进的批处理引擎相媲美。而在这根轴的另一头,是我今天的演讲将要说明的场景 – 事件驱动的应用。这类应用普遍存在于任何服务或者微服务的架构中。这类应用接收各类事件(可能是RPC调用、HTTP请求),并且对这些事件作出一些响应,比如把商品放进购物车,或者加入社交网络中的某个群组。
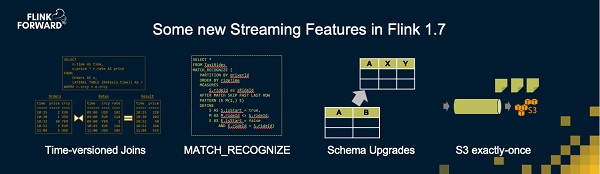
在我进一步展开今天的演讲之前,我想先对社区在Flink的传统领域(实时分析、连续处理)近期所做的工作做一个介绍。Flink 1.7在2018年11月30日已经发布。在Flink 1.7中为典型的流处理场景加入了一些非常有趣的功能。比如我个人非常感兴趣的在流式SQL中带时间版本的Join。一个基本想法是有两个不同的流,其中一个流被定义为随时间变化的参照表,另一个是与参照表进行Join的事件流。比如事件流是一个订单流,参照表是不断被更新的汇率,而每个订单需要使用最新的汇率来进行换算,并将换算的结果输出到结果表。这个例子在标准的SQL当中实际上并不容易表达,但在我们对Streaming SQL做了一点小的扩展以后,这个逻辑表达变得非常简单,我们发现这样的表达有非常多的应用场景。
另一个在流处理领域十分强大的新功能是将复杂事件处理(CEP)和SQL相结合。CEP应用观察事件模式。比如某个CEP应用观察股市,当有两个上涨后紧跟一个下跌时,这个应用可能做些交易。再比如一个观察温度计的应用,当它发现有温度计在两个超过90摄氏度的读数之后的两分钟里没有任何操作,可能会进行一些操作。与SQL的结合使这类逻辑的表达也变得非常简单。
 高层
高层 访谈
访谈

 观点
观点
