
搭建这样一个库并不难,难的是让它高性能的运行。让我们来看看它的性能。这些性能测试是几个月之前的,我们并没有做什么特别的优化,我们只是想看看一些最简单的方法能够有什么样的性能表现。而实际性能表现看起来相当不错。如果你看这些性能条形成的阶梯跨度,随着流处理器数量的增长,性能的增长相当线性。在事务设计中,没有任何协同或者锁参与其中。这只是流处理,将事件流推入系统,缓存一小段时间来做一些乱序处理,然后做一些本地状态更新。在这个方案中,没有什么特别代价高昂的操作。在图中性能增长似乎超过了线性,我想这主要是因为JAVA的JVM当中GC的工作原因导致的。在32个节点的情况下我们每秒可以处理大约两百万个事务。为了与数据库性能测试进行对比,通常当你看数据库的性能测试时,你会看到类似读写操作比的说明,比如10%的更新操作。而我们的测试使用的是100%的更新操作,而每个写操作至少更新在不同分区上的4行数据,我们的表的大小大约是两亿行。即便没有任何优化,这个方案的性能也非常不错。
另一个在事务性能中有趣的问题是当更新的操作对象是一个比较小的集合时的性能。如果事务之间没有冲突,并发的事务处理是一个容易的事情。如果所有的事务都独立进行而互不干扰,那这个不是什么难题,任何系统应该都能很好的解决这样的问题。当所有的事务都开始操作同一些行时,事情开始变得更有趣了,你需要隔离不同的修改来保证一致性。所以我们开始比较一个只读的程序、一个又读又写但是没有写冲突的程序和一个又读又写并有中等程度写冲突的程序这三者之间的性能。你可以看到性能表现相当稳定。这就像是一个乐观的并发冲突控制,表现很不错。那如果我们真的想要针对这类系统的阿喀琉斯之踵进行考验,也就是反复的更新同一个小集合中的键。在传统数据库中,这种情况下可能会出现反复重试,反复失败再重试,这是一种我们总想避免的糟糕情况。是的,我们的确需要付出性能代价,这很自然,因为如果你的表中有几行数据每个人都想更新,那么你的系统就失去了并发性,这本身就是个问题。但是这种情况下,系统并没崩溃,它仍然在稳定的处理请求,虽然失去了一些并发性,但是请求依然能够被处理。这是因为我们没有冲突重试的机制,你可以认为我们有一个基于乱序处理天然的冲突避免的机制,这是一种非常稳定和强大的技术。
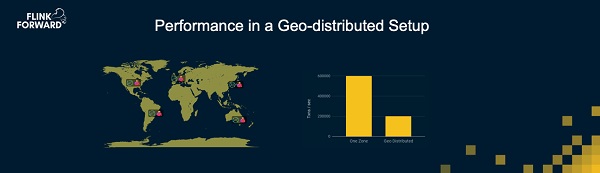
我们还尝试了在跨地域分布的情况下的性能表现。比如我们在美国、巴西,欧洲,日本和澳大利亚各设置了一个Flink集群。也就是说我们有个全球分布的系统。如果你在使用一个关系型数据库,那么你会付出相当高昂的性能代价,因为通信的延迟变得相当高。跨大洲的信息交互比在同一个数据中心甚至同一个机架上的信息交互要产生大得多的延迟。但是有趣的是,流处理的方式对延迟并不是十分敏感,延迟对性能有所影响,但是相比其它很多方案,延迟对流处理的影响要小得多。所以,在这样的全球分布式环境中执行分布式程序,的确会有更差的性能,部分原因也是因为跨大洲的通信带宽不如统一数据中心里的带宽,但是性能表现依然不差。实际上,你可以拿它当做一个跨地域的数据库,同时仍然能够在一个大概10个节点的集群上获得每秒几十万条事务的处理能力。在这个测试中我们只用了10个节点,每个大洲两个节点。所以10个节点可以带来全球分布的每秒20万事务的处理能力。我认为这是很有趣的结果,这是因为这个方案对延迟并不敏感。

我已经说了很多利用流处理来实现事务性的应用。可能听起来这是个很自然的想法,从某种角度上来说的确是这样。但是它的确需要一些很复杂的机制来作为支撑。它需要一个连续处理而非微批处理的能力,需要能够做迭代,需要复杂的基于事件时间处理乱序处理。为了更好地性能,它需要灵活的状态抽象和异步checkpoint机制。这些是真正困难的事情。这些不是由Ledger Streaming库实现的,而是Apache Flink实现的,所以即使对这类事务性的应用而言,Apache Flink也是真正的中流砥柱。
 高层
高层 访谈
访谈

 观点
观点
