在流处理中怎么解决这个问题呢?直觉上讲,如果我们能够让所有的事务都按照顺序依次发生,那么问题就解决了,这也被成为可序列化的特性。但是我们当然不希望所有的请求都被依次顺序处理,这与我们使用分布式系统的初衷相违背。所以我们需要保证这些请求最后的产生的影响看起来是按照顺序发生的,也就是一个请求产生的影响是基于前一个请求产生影响的基础之上的。换句话说也就是一个事务的修改需要在前一个事务的所有修改都完成后才能进行。这种希望一件事在另一件事之后发生的要求看起来很熟悉,这似乎是我们以前在流处理中曾经遇到过的问题。是的,这听上去像是事件时间。用高度简化的方式来解释,如果所有的请求都在不同的事件时间产生,即使由于种种原因他们到达处理器的时间是乱序的,流处理器依然会根据他们的事件时间来对他们进行处理。流处理器会使得所有的事件的影响看上去都是按顺序发生的。按事件时间处理是Flink已经支持的功能。
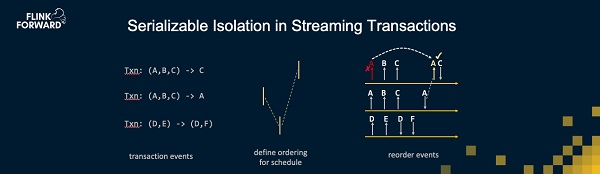
那么详细说来,我们到底怎么解决这个一致性问题呢?假设我们有并行的请求输入并行的事务请求,这些请求读取某些表中的记录,然后修改某些表中的记录。我们首先需要做的是把这些事务请求根据事件时间顺序摆放。这些请求的事务时间不能够相同,但是他们之间的时间也需要足够接近,这是因为在事件时间的处理过程中会引入一定的延迟,我们需要保证所处理的事件时间在向前推进。因此第一步是定义事务执行的顺序,也就是说需要有一个聪明的算法来为每个事务制定事件时间。在图上,假设这三个事务的事件时间分别是T+2, T和T+1。那么第二个事务的影响需要在第一和第三个事务之前。不同的事务所做的修改是不同的,每个事务都会产生不同的操作请求来修改状态。我们现在需要将对访问每个行和状态的事件进行排序,保证他们的访问是符合事件时间顺序的。这也意味着那些相互之间没有关系的事务之间自然也没有了任何影响。比如这里的第三个事务请求,它与前两个事务之间没有访问共同的状态,所以它的事件时间排序与前两个事务也相互独立。而当前两个事务之间的操作的到达顺序与事件时间不符时,Flink则会依据它们的事件时间进行排序后再处理。
必须承认,这样说还是进行了一些简化,我们还需要做一些事情来保证高效执行,但是总体原则上来说,这就是全部的设计。除此之外我们并不需要更多其他东西。
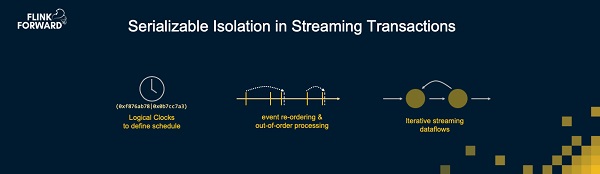
为了实现这个设计,我们引入了一种聪明的分布式事件时间分配机制。这里的事件时间是逻辑时间,它并不需要有什么现实意义,比如它不需要是真实的时钟。使用Flink的乱序处理能力,并且使用Flink迭代计算的功能来进行某些前提条件的检查。这些就是我们构建一个支持事务的流处理器的要素。
![~]0OV$72_]RUH131WYGK2ZY.jpg](http://www.hnetn.com/upLoadFile/2019/4/19/201941911575436.jpg)
我们实际上已经完成了这个工作,称之为流式账簿(Streaming Ledger),这是个在Apache Flink上很小的库。它基于流处理器做到了满足ACID的多键事务性操作。我相信这是个非常有趣的进化。流处理器一开始基本上没有任何保障,然后类似Storm的系统增加了至少一次的保证。但显然至少一次依然不够好。然后我们看到了恰好一次的语义,这是一个大的进步,但这只是对于单行操作的恰好一次语义,这与键值库很类似。而支持多行恰好一次或者多行事务操作将流处理器提升到了一个可以解决传统意义上关系型数据库所应用场景的阶段。
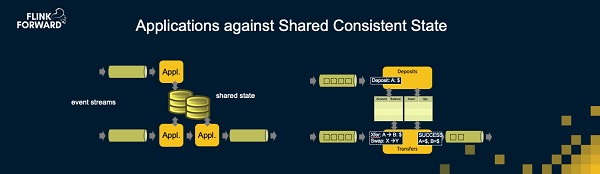
Streaming Ledger的实现方式是允许用户定义一些表和对这些表进行修改的函数。Streaming Ledger会运行这些函数和表,所有的这些一起编译成一个Apache Flink的有向无环图(DAG)。Streaming Ledger会注入所有事务时间分配的逻辑,以此来保证所有事务的一致性。
 高层
高层 访谈
访谈

 观点
观点
